Quantify epistatic coefficient uncertainty with MCMC¶
Point estimates from linear regression tell you the most-likely epistatic coefficients, but not how certain those estimates are. BayesianSampler wraps a fitted epistasis model in an MCMC ensemble sampler, draws from the posterior distribution over model parameters, and lets you compute percentile confidence intervals on every coefficient without making Gaussian assumptions.

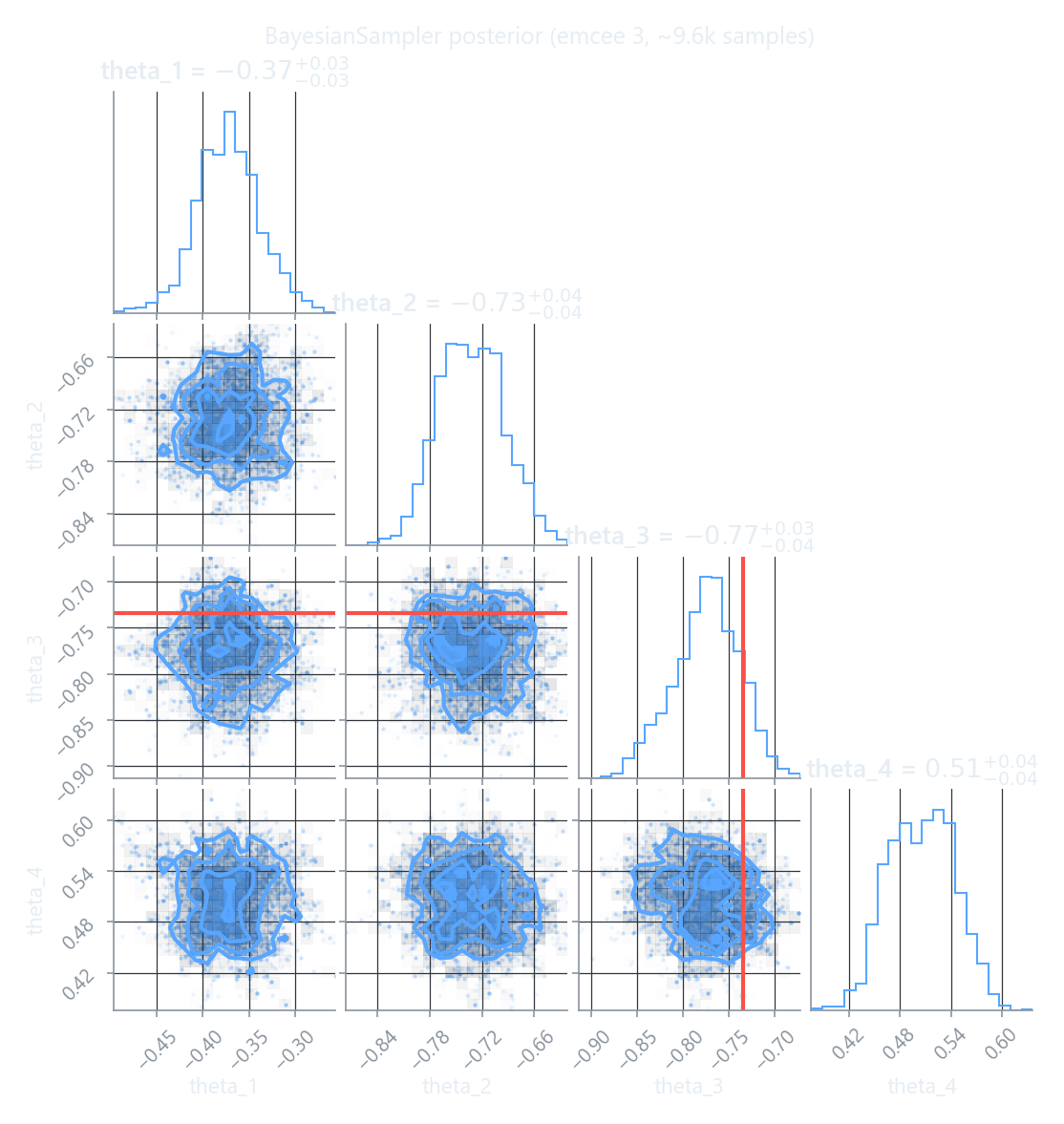
A corner plot of the posterior shows the marginal distribution of each coefficient on the diagonal and the pairwise correlations off-diagonal; the red lines mark the true simulated values.
When to use Bayesian sampling¶
Use BayesianSampler after you have fitted an epistasis model and want to answer questions like: "Is this pairwise coefficient meaningfully different from zero?", "How wide is the credible interval on the intercept?", or "Do any high-order coefficients have posteriors that overlap zero?" MCMC is slower than point estimation, so apply it once you have selected your model order through cross-validation.
Note
BayesianSampler uses the emcee 3 affine-invariant ensemble sampler. Install it with pip install emcee if it is not already in your environment.
What the model must expose¶
BayesianSampler requires the fitted model to satisfy the SamplerModel protocol:
model.thetas: anp.ndarrayof the fitted parameter vector (the ML estimates used to seed walkers).model.lnlikelihood(thetas=...): a callable that returns the log-likelihood at a given parameter vector.
All built-in epistasis-v2 linear models satisfy this interface after calling .fit().
BayesianSampler¶
from epistasis.sampling.bayesian import BayesianSampler
sampler = BayesianSampler(model, lnprior=None, n_walkers=None)
Parameters¶
model(SamplerModel, required)- A fitted epistasis model exposing
thetasandlnlikelihood(thetas=). Callmodel.fit()before constructing the sampler. lnprior(Callable[[np.ndarray], float] | None, defaultNone)- A log-prior function over the parameter vector. Receives
thetasas anp.ndarrayand returns a scalar float. Defaults to a flat (improper uniform) prior:lambda thetas: 0.0. Supply a custom function to impose regularizing priors, e.g., a Gaussian prior on coefficient magnitudes. n_walkers(int | None, defaultNone)- Number of ensemble walkers. Defaults to
2 * ndim, wherendimis the length ofmodel.thetas. Must be at least2 * ndim. More walkers improve mixing at the cost of proportionally more likelihood evaluations per step.
sampler.sample¶
sample runs the MCMC chain and returns a flat array of shape (n_steps * n_walkers, ndim), every accepted sample across all walkers, ready for percentile computations.
Parameters¶
n_steps(int, default500)- Number of production steps after burn-in. The flat chain will contain
n_steps * n_walkersrows. n_burn(int, default100)- Number of burn-in steps to discard before collecting samples. The sampler resets after burn-in so these steps do not appear in the flat chain. Pass
n_burn=0on subsequent calls to continue from the last state without discarding any steps. progress(bool, defaultFalse)- Show a
tqdmprogress bar during sampling. Useful for long runs in interactive sessions. rng(np.random.Generator | None, defaultNone)- A NumPy random generator used to seed the initial walker positions. Pass a seeded generator for reproducible starting points.
sampler.chain¶
sampler.chain exposes the non-flat chain after sampling. Use it to inspect per-walker traces, compute autocorrelation times, or diagnose convergence.
sampler.initial_walkers¶
Returns walker starting positions as a Gaussian cloud around the ML parameter estimates. The width of the cloud scales per coefficient: scale = relative_width * |theta_i|. Coefficients near zero use relative_width as the absolute scale.
Parameters¶
relative_width(float, default1e-2)- Width of the initialization cloud relative to each coefficient's magnitude.
rng(np.random.Generator | None, defaultNone)- A NumPy random generator for reproducible initialization.
sample calls initial_walkers automatically on the first call, so you only need to call it directly if you want to inspect or customize the starting positions.
Complete example¶
The following example fits a second-order linear model, runs MCMC to sample the posterior, and prints 95% credible intervals for every epistatic coefficient.
import numpy as np
from epistasis.simulate import simulate_random_linear_gpm
from epistasis.models.linear import EpistasisLinearRegression
from epistasis.sampling.bayesian import BayesianSampler
# --- 1. Simulate a known GPM ---
rng = np.random.default_rng(42)
wildtype = "AAAA"
mutations = {0: ["T"], 1: ["T"], 2: ["T"], 3: ["T"]}
gpm, sites, true_coefs = simulate_random_linear_gpm(
wildtype=wildtype,
mutations=mutations,
order=2,
coefficient_range=(-1.0, 1.0),
stdeviations=0.05, # add measurement noise so the posterior is non-trivial
rng=rng,
)
# --- 2. Fit the model ---
model = EpistasisLinearRegression(order=2, model_type="global")
model.add_gpm(gpm)
model.fit()
print(f"Fitted {len(model.thetas)} parameters")
# --- 3. Run MCMC ---
sampler = BayesianSampler(model, n_walkers=None) # defaults to 2 * ndim walkers
flat_chain = sampler.sample(
n_steps=500,
n_burn=100,
progress=True,
rng=np.random.default_rng(0),
)
print(f"Flat chain shape: {flat_chain.shape}") # (n_steps * n_walkers, ndim)
# --- 4. Compute 95% credible intervals ---
lo, hi = np.percentile(flat_chain, [2.5, 97.5], axis=0)
print("\nSite | True | ML estimate | 95% CI")
print("-" * 60)
for i, site in enumerate(sites):
print(
f"{str(site):<20} "
f"true={true_coefs[i]:+.3f} "
f"ml={model.thetas[i]:+.3f} "
f"CI=[{lo[i]:+.3f}, {hi[i]:+.3f}]"
)
Extending the chain¶
If you want more samples without discarding the current state, call sample again with n_burn=0:
# Initial run
flat_chain = sampler.sample(n_steps=200, n_burn=100)
# Extend without re-burning
more_samples = sampler.sample(n_steps=800, n_burn=0)
# Combine
all_samples = np.concatenate([flat_chain, more_samples], axis=0)
Tip
Check convergence by plotting the per-walker traces from sampler.chain (shape (n_steps, n_walkers, ndim)). Well-mixed chains look like overlapping noise; chains that drift or cluster indicate the sampler has not converged and you need more steps or better initialization.
Supplying a custom log-prior¶
To impose a regularizing prior, for example a zero-mean Gaussian on all coefficients, pass a lnprior function:
import numpy as np
from epistasis.sampling.bayesian import BayesianSampler
sigma = 2.0 # prior standard deviation on each coefficient
def gaussian_lnprior(thetas: np.ndarray) -> float:
return float(-0.5 * np.sum((thetas / sigma) ** 2))
sampler = BayesianSampler(model, lnprior=gaussian_lnprior)
flat_chain = sampler.sample(n_steps=500, n_burn=100)
The log-prior is added to the log-likelihood at every step. Return float("-inf") from lnprior to hard-reject parameter values outside a feasible region.